








드로우홀릭 더베이직
대용량 연구 데이터 관리 사례를 알아봅니다.
10~15분 간격으로, 위도/경도 격자의 미세먼지 등의 기상 데이터를 저장하는 데이터베이스입니다.
10여년 간 8TB바이트의 데이터가 있습니다. (300억건)
4시간 걸렸던 데이터 조회 시간이, 5분으로 단축되었습니다.
어떻게 해서 이런 작업이 가능했던 것인지 알아보겠습니다.
00:00 시작
01:42 어느 정도의 대용량인가요?
04:28 관리 프로그램 살펴보기
05:10 어떤 데이터인가요?
05:46 데이터 추출하는 방법 알아보기
09:37 어떤 문제를 해결했습니까?
12:13 어떻게 문제를 해결했을까요?
13:25 시놀로지 나스의 문제점
16:05 문제 해결: 하드웨어 변경
17:17 문제 해결: DB의 기본적 속성 변경
18:22 문제 해결: 튜닝
19:00 DB 튜닝 사례: 인터넷 쇼핑몰
21:27 문제 사례: 과다한 재고 조회 시간
24:50 문제 해결: 자료구조 변경
27:12 문제 해결: 테이블 파티셔닝



----------------------------------------------------------------------------------------------
여기부터는 위 동영상의 음성을 텍스트로 변환한 것입니다.
(검색이 잘 되도록 하기 위해 작성한 것입니다.)
----------------------------------------------------------------------------------------------
돌직구:
안녕하세요. 오늘은 '대용량 연구 데이터 관리'에 대해서 한번 알아보겠습니다.
대략, '대용량 연구 데이터,' 데이터 되게 많이 쌓이는 거겠죠?
뭔지 알겠는데, 얼마나 대용량입니까?
윈드님:
약 300억 건 정도 되고요. 300'억' 건
돌직구:
300억이요?
윈드님:
네, 그리고 약 8년치 데이터입니다.
돌직구:
8년치, 300억 건 어마어마하네요.
데이터 용량은 얼마나 돼요?
윈드님:
8TB요.
돌직구:
아니 300억 건이 8TB? 고용량 하드가 요새 수십 TB가 넘는데, 8TB는 너무 적은 거 아닙니까?
윈드님:
저도 고용량 하드를 좀 많이 갖고 있거든요?
돌직구:
뭐 있어요? 그 하드에?
윈드님:
알려고 하지 마세요.
돌직구:
나도 좀 주지.
윈드님:
알려고 하지 마세요. 비밀이에요.
그 고용량 하드에 그 영상들을 저장하니까, 그렇게 적다고 느끼는 거지…
DB는 기본적으로 텍스트 데이터예요.
텍스트 데이터로 8TB는, 정말 많은 거예요.
돌직구:
글쎄요, 그래도 감이 좀 잘 안 오는 분이 있을 수 있을 것 같은데.
윈드님:
좋아요, 그러면은 이렇게 말씀드릴게요.
저희가 개발한 ERP를 사용하는 고객이 있어요.
지금 연 매출 한 3에서 4천억 정도 하는 생산 회사인데.
여기가 지금 10년이 넘었는데, 그 용량이 10GB가 안 돼요.
돌직구:
TB가 아니라. 10GB요?
윈드님:
그렇죠. 10GB가 안 되는 거예요.
돌직구:
여기, 그림에서 8TB랑, 그 다음에 10GB…
윈드님:
그렇죠 이만하죠? 요만하죠?
비교를 해보면, 격하게 차이가 나지요.
돌직구:
하긴, 이게 ERP가 아니라 MES면, 데이터 용량이 좀 많이 될 수는 있을 텐데…
알겠습니다. 그래도 감이 좀 잘 안 와요.
윈드님:
그렇죠. 그럼 설명을 좀 더 드릴게요.
일단 텍스트 데이터라는 게, 텍스트 데이터의 용량이라는 게, 일반인들이 생각하는 거랑은 좀 많이 달라요.
그래서 제가 예를 하나 들어볼게요.
'퇴마록', 저희는 정말 재미있게 봤던 책입니다.
소설책 한 권 분량 기준으로 해서…
돌직구:
이거 보는 사람들이 우리랑 연령대가 맞겠죠?
20대가 보고 그러진 않을 것 같은데.
윈드님:
아마도?
돌직구:
20대 분들은 '퇴마록' 모를 거 아니에요.
30대는 알려나?
윈드님:
책 좋아하는 사람은 알 수 있겠죠.
'퇴마록' 한 권 정도를 텍스트로 담는다고 했을 때…
돌직구:
텍스트 파일로 만든다고 했을 때.
윈드님:
네, 1TB면 '퇴마록'이 200만 권이 들어가요.
소설책 200만 권이 들어가고…
돌직구:
어마어마하네요. 도서관이 들어가네요, 도서관이…
윈드님:
10GB면 '퇴마록' 2만 권, 도서가 2만 권이 들어가는 거예요.
돌직구:
그러니까, 우리가 이 연매출 3천~4천억 제조회사의 ERP가 10GB가 안 된다는 게, 여기가 실제로 장부를 지금 2만 권을 썼다는 얘기네요.
윈드님:
2만권 분량을 쓴 거죠.
돌직구:
그래서 텍스트, 10GB는 굉장히 많은 용량이다.
윈드님:
예 맞아요. 동영상 같은 거는 그런 용량의 낭비가 엄청 심하다고 볼 수도 있죠.
돌직구:
굳이 말하자면. 동영상은 이 점 하나하나가 요새 32Bit 컬러니까, 16,000,000에 2인가?
하여튼, 그 칼라 색상을 갖고 있으니까.
근데 그거를 우리가 다 구분을 못하죠.
그러니까 좀 '낭비가 있다'라고 볼 수는 있을 것 같아요.
좋아요, 되게 많은데 300억 건에 8TB…
이건 뭐 하는 데이터입니까?
윈드님:
이게, 연구 데이터예요. 이 안에는 여러 가지가 있는데.
그 중에서 '대기질'이라는 데이터에 대해서만 말씀을 드릴 거예요.
네, 그럼 화면을 좀 볼게요.
이런 프로그램이 있고, 프로그램 자체는 되게 간단한 겁니다.
돌직구:
네, 방금 뭐 하신 거예요?
윈드님:
방금 로그인 한 거죠. 아이디, 패스워드 넣고 그냥 로그인을 한 거고.
이제부터 되게 간단한 설명과 함께 잠깐 보내드릴게… 말씀을 드릴게요.
돌직구:
어디를 보내? 홍콩?
윈드님:
나도 갔으면 좋겠다…
보여드릴 게요. 일단은 '대기질'에 가면, '대기질 추출 요청'이라는 게 있어요.
결국 이거는 뭐냐 하면, 그 많은 데이터 중에서 우리가 원하는 데이터를 요청하는 거예요.
데이터를 주세요 해서. 받아오기 위해서 하는 거고요.
이 화면 자체는…
돌직구:
잠깐만요. 누구한테 달라고 하는 거에요?
윈드님:
서버한테요.
돌직구:
아, 컴퓨터한테? 왜 그래요? 그냥 내가 조회하면 나오면 되지 않아요?
윈드님:
데이터 수가 얼마 없는 애들은, 누르면 바로 나오니까 그게 되겠죠.
돌직구:
데이터가 많아서. 시간이 오래 걸리니까?
윈드님:
그렇죠, 얘는 데이터가 많고. 시간이 오래 걸려서, 바로 나오는 게 아니기 때문에 요청을 서버가 하면, 서버가 나중에 그거를 처리를 해주고, 이메일로 알려주는 거예요.
'다 됐습니다' 라고 메일 주면, 내가 그때 가서 파일 받아오면 되는 거고.
지금 보시는 이 화면은 그 데이터 요청을 하기 위해서, 조건들을 넣어주는 거예요.
돌직구:
근데 무슨 데이터냐고요?
윈드님:
이 데이터가 무슨 데이터냐면은, 우리 대기 중에 있는 어떤 요소들을 '미세먼지'라든가, '초미세먼지' 이런 것들을 일자별로 수집하는 데이터인데.
이거를 보시면 이게 대한민국 지도예요.
대한민국 지도에, 이렇게 격자 모양으로 구획을 나눠서.
이게 위도, 경도로 되어 있는 거거든요?
그 안에 있는 데이터들을 수집을 해요. 그 데이터를 우리는 추출을 하는 거고
돌직구:
잠깐만요. 그럼 제가 이해한 게 맞나 봐주세요.
우리나라를 이렇게 격자로 다 나눠요, 어떤 지역을.
여기쯤이 되려나? 서울, 어디가 되겠죠. 그럼 이 칸에 미세먼지가 오늘 얼마였다. 오늘 1시에 얼마였다, 오늘 2시에 얼마였다.
이런 데이터들을 쭉 쌓아서 넣어놓은 데이터군요?
윈드님:
그렇죠. 그게 300억 건이 있는 거예요.
돌직구:
무슨 말인지 알겠습니다.
윈드님:
그 데이터를 뽑아야 되는 거예요.
우리가 지금 얘기한 거랑 똑같아요.
지금 화면 보시면, 언제부터 언제 거. 그 다음에 그 데이터도 여러 가지 종류들이 있거든요.
어떤 데이터를, 여기 보시면 위, 경도라고 되어 있죠?
여기다가 위도와 경도를 입력하면. 하나 입력하면, 이 화면에 어느 한 격자의 데이터를 갖고 오는 거예요.
그래서…
돌직구:
그러니까, 정확한 위, 경도를 몰라도, 대략 이 박스 안에 들어가면 걔로 인식하고 그러나요?
윈드님:
그렇죠. 자동으로 가까운 유경도를 찾아내요.
그럼 얘가 하나가 아니고 여러 개를 입력한다?
그러면은 말 그대로 여기서, 여러 격자의 점이라고 제가 표현할게요.
이거는 위, 경도고요. 그 다음에 여기 또 '시군구'라고 있어요.
우리가 '경기도,' '성남시' 이렇게 선택을 하면, 경기도 성남시의 모든 격자의 데이터들을 갖고 오겠다는 얘기죠.
돌직구:
주소를 치면? 위, 경도가? 그러니까 데이터는 위, 경도 기반으로 저장돼 있는데, 그게 변환이 되나 봐요.
신기한데?
윈드님:
그래서 특정 지역의 전체를 갖고 올 수 있는 거예요.
이렇게 해서 '추출 요청'을 누르면 우리는 서버한테 얘기하는 거예요, '이 데이터 주세요'라고 하면 서버는, '알겠다.' 그리고 그 요청 리스트를 갖고 있어요.
그래놓고 얘가 하나씩, 하나씩, 처리를 하는 거죠.
이런 것처럼 누가 요청했고, 상태, '취소,' '완료,' '보류,' 이런 식으로 해서요.
'취소'는 내가 취소를 한 걸 거고…
돌직구:
이건 뭐예요?
윈드님:
아까 말씀드렸지만, 제가 방금 전에 요청을 했잖아요. 그럼 그 요청한 게 여기 리스트로 남아 있는 거예요.
돌직구:
요청 이력?
윈드님:
네, 누가 언제 어떤 데이터를, 그리고 그거에 대한 상태.
끝나면, 완료가 되고, 완료가 되는 시점에 이메일로 오는 거죠.
돌직구:
그러니까 완료가 되니까, 그 옆에 이렇게 파일명이 있군요.
윈드님:
그렇죠. 완료가 된 거니까.
돌직구:
그럼 이메일에서 링크 클릭하면, 파일 다운받고 이게 되는 거구나
윈드님:
그렇죠.
돌직구:
알겠습니다.
윈드님:
프로그램에 대한 설명은 이게 다예요.
되게 간단해요, 프로그램 자체가.
돌직구:
물론 여기 보면 다른 것도 더 있겠죠.
근데 '대기질'만 보면. 그리고 이게 다른 것보다 이 '대기질' 얘가 핵심이라고, 제가 들었던 것 같은데?
윈드님:
가장 많은 데이터를 갖고 있네요.
돌직구:
아니 이거 되게 간단한데, 이거를 돈 받고 해줬다고요?
윈드님:
싸울래요?
돌직구:
아니, 용팔입니까?
윈드님:
그럼 손님, 맞을래요?
돌직구:
아이고, 참.
윈드님:
진정하시고, 오늘 따라 좀 들뜨셔서 도발이 좀 많이 들어오시는데요?
돌직구:
말은 자기가 했으면서…
윈드님:
아니죠. '이걸 돈 받고 해줬냐?' 이게 도말이죠
돌직구:
그런가? 너무 심했나. 너무 간단해서…
윈드님:
이게 뭐 간단해요. 이 문제는 데이터가 너무 많다는 거예요.
많아도 너무 많죠. 300억 건.
돌직구:
많긴 많네요.
윈드님:
그러면은 이 연구원들이…
돌직구:
300억 감이 안 와요.
윈드님:
300억이 감이 안 와요? 300억 원 하면.
감이 오시려나?
돌직구:
감이 안 오죠.
윈드님:
로또를 한 10번 맞아야 되는 300억 원?
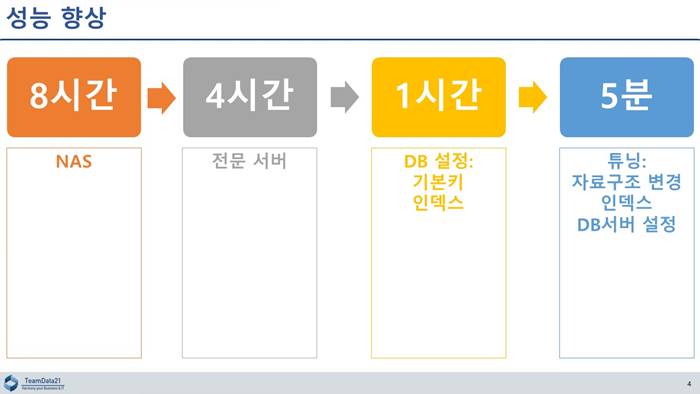
연구원들이 원래는 데이터 하나 뽑으려고 할 때, 8시간 정도 걸렸대요.
우리가 이걸 작업하기 전에.
8시간이 걸렸어요.
돌직구:
8시간이요? 그러니까, 연구원들이니까.
서버는 한 대고. 내가 한 번 요청하면, 8시간 동안 그 서버를 중복으로 할 수 있겠지만 느려질 테니까.
일단은 못 쓴다고 봐야겠죠?
윈드님:
그렇죠. 그건 기다려야 되는 거죠. 그리고 한 사람이 끝날 때까지.
그리고 그 '8시간'이라는 게 전체 데이터를 뽑을 때 걸리는 시간이 아니라는 거예요.
돌직구:
일부 필터링 했을 때 8시간 걸린다?
전체 데이터를 다 뽑을 일은 없지 않을까요?
윈드님:
그런데 그 일이 일어났습니다… 여기는 가끔 그렇게 뽑기도 한대요.
돌직구:
전체 세트를 다 뽑는다?
윈드님:
그렇게 뽑는 데 한 일주일 걸린대요.
돌직구:
그럼 일주일 사이에 오류라도 생기면?
네트웍이 끊어진다든지…
윈드님:
'깊은 빡침'이 뭔지 아는 거죠. 신나게 룰루랄라하다가, '됐겠지' 하고 딱 봤는데, '오류' 이러고 있으면 환장하는 거죠.
돌직구:
아니 연구원이 연구하는 데 시간을 쏟는 게 아니라, 기다리는 게 일일 것 같은데요?
윈드님:
그렇죠. DB 때문에 인류가 대용량 데이터를 다룰 수 있게 됐는데, 기다리는 시간도 같이 얻었어요. 그래서 저희가 먹고 사는 거죠.
돌직구:
명언이네요. 그래서 8시간 돌렸다고 칩시다.
우리가 얼마나 단축했어요?
윈드님:
자 놀라지 마세요. 결론적으로 8시간이, 5분으로 갔어요
돌직구:
8시간이 5시간이 아니고?
윈드님:
5시간이 아니고 5분. 5시간이면 돈 못 받죠.
돌직구:
대단하네요.
윈드님:
한 번에 그렇게 된 건 아니고요. 저희도 연구를 많이 했어요.
돌직구:
뭘 했어요?
윈드님:
일단은 조사를 해보니까, 기존에 돌고 있던 게 시놀로지 NAS에서 DB가 돌고 있더라고요.
개인용 나스는 아니고, 그 서버처럼 생긴 업무용 NAS장비이긴 했는데.
이게 대용량 데이터 저장은 가능하죠, 스토리지가 크니까.
근데 NAS는 CPU랑 메모리가 부족해요.
이게 고성능의 CPU라든가… 많은 메모리를 넣지 못했죠.
그랬더니 실제로 이게 돌다가 메모리 부족 오류 같은 게 생겨 갖고, 오류가 막 떨어지고 그랬어요.
그래서 저희랑 논의를 해서 전문 서버로 옮긴 거예요.
돌직구:
그런 사례 되게 많아요. 저도 시놀로지 나스에 대해서 좋은 게 되게 많아요.
우리 회사는 지금 Dropbox로 백업하고 있는데.
그건 매달 돈이 나가는 데, 꽤 나가거든요?
그래서 그거를 시놀로지를 사서 보니까, Dropbox랑 비슷한 게 있더라고요.
그래서 그걸 테스트를 막 해봤는데…
우리 회사는 파일이 너무 많아가지고, 그건 안 되는 거예요.
그래서 그것뿐만 아니고, 시놀로지에 있는 앱 되게 많아요.
근데 보니까 데이터가 좀만 많거나, 사람이 좀 많거나, 이러면 안 되겠더라고요.
그러니까 그냥 NAS도 DB로 쓸 수 있죠.
근데 업무용으로 써먹을 만하지는 않은 것 같아요, 진짜 간단한 거 아니면은.
하여튼 그래서 하여튼 저는 처음에 이제 시놀로지 보고, '진짜 우리나라가 나아가야 될 게 이거다.대만에 있는 한 회사가 소프트웨어 엄청 개발해가지고 정말 대단하다' 했는데 실제로 이제 좀 테스트 좀 해보고 조금 실망은 하기는 했고.
그래서 지금도 시놀로지 관리하려다…
왜 지금 갑자기 시놀로지 디스를 하게 되었는지 모르겠는데…
시놀로지 좋습니다. 그 파일 서버로 쓰고 이러면 좋은데.
제 말은, 거기에 더 붙어 있는 앱 있죠? 그거는 진짜 나 혼자 쓰거나, 두 사람 쓰거나, 이러면 모르겠는데.
예를 들어 30명짜리 회사가 NAS 장비 좋은 거 산다고 그거 같이 쓰고, 이게 안 되는 거예요.
성능이 안 받쳐줘가지고.
원래 그리고 파일 서버가, 제일 안 좋은 CPU나 메모리로도 충분히 커버가 되는, 그런 서버이기도 하니까요.
그래서 저는 시놀로지 앱 같은 거를 그냥 간단하게만 쓰시는 걸 권장을 드립니다.
그래서 전문 서버로 한 다음에, 성능이 어느 정도로 향상이 됐습니까?
윈드님:
일단 첫 번째로 서버를 옮기니까 메모리 부족 같은 걸로 해서 오류나 현상은 없어졌고.
방금 질문하신 시간은…
돌직구:
잠깐만요. 그래서 때로는 하드웨어가 답이긴 해요.
서버로 그냥 옮기기만 하니까, 메모리 부족으로 오류 나는 현상이 없어졌다.
그렇죠 제 질문은, '시간이 얼마나 단축되던가' 였는데요?
윈드님:
그래서 물어보는거에 대답하려고 그랬는데 끊으셨잖아요?
시간을 한 4시간으로 줄었어요.
8시간에서 4시간으로.
돌직구:
그럼 하드웨어만으로는 한 50% 정도 효과를 본 거네요?
윈드님:
그렇죠. 근데 제가 처음에 얘기했던 8시간에서 5분까지.
돌직구:
그렇죠. 결론은 5분이라고 그랬죠? 아직 한 개 더 많이 있단 얘기네요.
윈드님:
그렇죠, 가야 될 길은 멀어요. 일단은, 이곳에서는 DB에 대한 전문 지식이 없었어요.
좀 부족했던 거죠. 그래서 테이블 자체를 보니까, 기본기도 안 돼 있고, 인덱스 같은 것도 하나도 안 잡혀 있었어요.
돌직구:
여기 DB는 뭐였어요?
윈드님:
DB요? MySQL.
돌직구:
마리아 DB?
연구소들이, 마리아 DB가 라이센스 비용이 안 드니까, 많이 쓰는데.
문제는 DB에 대한 깊은 이해 없이, 일단 데이터 저장해놓고 쓰는 거죠.
그러니까 이제 느린 거죠.
윈드님:
설명이 좀 복잡하지만 그 인덱스 잡는 것도 되게 어려웠을 거고요.
자료 구조상도 문제가 좀 있었어요. 일단은 원래 자료 구조를 그냥 유지하면서, DB 설정을 좀 바꿔주고 해서, 1시간 정도의 자료를 뽑아낼 수 있었어요.
8시간, 4시간, 1시간.
돌직구:
그러니까. 서버로 바꾸니까 4시간, 그죠?
그러니까 베이스를 이걸로 봐야겠네요, 4시간.
윈드님:
그렇게 봐야 되겠죠.
돌직구:
결국 5분이 됐는데. NAS 대비 5분이 됐다. 이렇게 얘기하면 좀 어폐가 있고.
전문 서버에 해서 4시간을 했는데 우리가 작업했더니 5분이 됐다.
윈드님:
그렇죠.
돌직구:
그것도 대단한 겁니다. 4시간이 5분이 되다니.
윈드님:
그렇죠.
돌직구:
75% 정도 되는데, 진짜 대단한 성과입니다.
윈드님:
그렇죠. 근데 이제 1시간에서 5분으로 가야죠.
그래서 최종적으로 아까 말씀드렸던 자료 구조에 문제가 좀 있다고 그랬었잖아요, 제가?
그래서 그 자료 구조를 건드렸어요.
그거에 대해서 추가적인 비용이 들기는 했지만 자료 구조 문제를 건드리고 나니까, 1시간이 5분이 된 거예요.
돌직구:
그래서 뭘 어떻게 했는데요?
윈드님:
대용량 데이터 처리를 할 때는요.
튜닝의 영역으로 넘어가야 돼요.
돌직구:
제가 아는 SQL서버 튜닝 업체 있는데…
그 사람들 단가가 시간당 몇 십만 원입니다. 하여튼 근데, 그분들이…
제가 재미있는 얘기 해드릴게요.
그분들이 이제 인터넷 쇼핑몰 사이트를 튜닝을 한 거예요.
쇼핑몰 사이트는 첫 페이지에 '그림' 이런 게 되게 많잖아요?
윈드님:
그렇죠 엄청 많이 있죠.
돌직구:
첫 페이지 로딩 시간이 20초 정도 걸렸대요. 되게 오래 걸린 거예요, 손님 다 떠나가죠.
그래서 이거를 튜닝을 해가지고, 1초 미만으로 줄였다는 전설 같은 얘기를 제가 들었어요.
'그래서 몇 초 됐어요? 한 2, 3초 됐어요? 그랬더니, '아니요, 1초 미만이에요.'
그러니까 한번에 팍 뜨는 거죠.
윈드님:
근데 그 쇼핑몰이 어떤 건데요? 중소에요?
돌직구:
그거를 말씀드리긴 좀 그렇고, 그냥 초대형?
우리가 다 아는 쇼핑몰이에요, 얘기하면 딱 알아요.
여기도 되게 웃긴 게, 튜닝 업체 컨택하기 전까지, 일단 누구나 하드웨어 업그레이드 먼저 하려고 했대요.
그래서 실제로 제가 그냥 들은 말이라…
건너, 건너들은 말은 아니니까 신빙성은 있는 말이고요.
직접 했던 분한테 들은 말이니까.
실제로 하드웨어 업그레이드를 해보고 나서, 안 되니까 튜닝 업체를 부른 건지.
처음부터 그냥 튜닝 쪽으로 바로 했는지는 확실치는 않아요.
근데 이제 누구나 일단 생각하는 게 하드웨어 쪽이죠.
'야, 메모리 없잖아, 메모리 맨날 80%, 90% 되잖아. 메모리 늘려!'
이런 게 일반적인 의사 결정이잖아요?
우리가 봤을 땐 바보 같은 결정이지만.
근데 이제 원인을 좀 찾고, 걔를 소프트웨어적으로 해결하는 것이, 좀 성과가 더 좋을 때가 많죠.
그래서 보통 제 경험으로는, 하드웨어 업그레이드해서 얻을 수 있는 성과는, 두, 세 배 나오기 힘들어요.
대부분 한 20% 좋아지고, 30% 좋아지고 이런 게 대부분인데…
소프트웨어 성과는 수십 배, 수백 배도 나오거든요.
우리도 지금 4시간에서 5분이면 이게 몇 배야?
엄청난 거죠. 그래서 이거는 하드웨어로 할 수 있는 게 아니에요.
4시간 걸리던 작업을 백날 해보세요.
슈퍼 컴퓨터에 돌리면 좀 나으려나?
그러니까 소프트웨어적인 성과가 수십 배, 수백 배 나오기 때문에, 저는 여러분들이 이제 그런 걸 좀 알고 계셨으면 좋겠어요.
윈드님:
저도 그런 사례를 좀 몇 개 알고 있는데, 실제로 ERP에서 '재고 조회'를 해야 되는데, '재고 조회' 버튼을 누르면 결과가 나올 때까지 20분이 걸린대요.
돌직구:
직접 들은 거 맞아요? 그게 말이 돼요?
그걸 누가 써요~
윈드님:
그게 우리나라 중소기업의 현실입니다…
이것도 저한테 문의를 했었어요.
이 회사가 ERP 업체한테 처음에 얘기를 했었겠죠.
돌직구:
'왜 이렇게 오래 걸리냐?'
윈드님:
그랬더니…
돌직구:
거기 혹시, 처음에는 잘 됐는데 한 2, 3 년 지나고 데이터가 쌓이니까 느려진 거 아니에요?
그렇죠! 대부분 그래요.
윈드님:
근데 돌아온 답은, '하드디스크를 좋은 SSD로 교체하세요.'
3천만…
돌직구:
3천만 원?
윈드님:
서버용 SSD는 좀 비싸요. 그래서 저한테 연락을 주신 분은.
'그럼 하드웨어 교체 말고 좀 더 좋은 방법이 있나, 없나' 이런 걸 문의를 하신 거였어요.
돌직구:
제가 봤을 때는 그분이 더 좋은 방법이 있냐고 말은 했겠지만, 엄청 괘씸한 거죠.
그런 거 되게 많거든요.
아니 이건 말이 안 되잖아요, 상식적으로 20분이라는 게.
근데 그 놈들은…
내가 확실히 본 건 아니니까.
안 봐도 비디오인 게, 그 놈들 아마 그랬을 거예요.
'이거 뭐 서버가 오래돼서 그래요. 서버가 느려서 그래요.
데이터 쌓이면 당연히 그러는 거예요.'
뭐 이랬을 걸요? 나쁜 놈들.
윈드님:
그럴 가능성이 높아요. 그래서 제가 튜닝 업체를 하나 알려주고.
한번 알아보라고 했던 기억이 나요.
돌직구:
그래서 결론이 어떻게 됐어요?
윈드님:
경영진에서요, SSD교체, 3천만 원 '오케이'를 하고 튜닝비가 2천만 원이 나왔는데, 견적이, 튜닝비 2천만 원은 '노' 해가지고 결국 SSD를 구매했고.
돌직구:
아니 잠깐만. 튜닝비가 더 싼 거잖아요?
2천만 원, 그러니까 1천만 원 싼 거잖아요.
근데, 그 마음 알지.
윈드님:
나도 뭔지 알 것 같긴 한데…
돌직구:
SSD는 우리 거고, 남는 건데.
튜닝은 인건비인데.
그 사람들 잠깐 와서, 나가면 우리 거 남는 거 없는 것 같고.
윈드님:
그렇죠. 아무튼 그래서 20분 걸리던 게 SSD를 바꾼 다음에 17분 걸린대요.
그게 마지막 소식이었어요, 저랑.
돌직구:
3천만 원에 3분 단축? 황당한 사례네요.
윈드님:
그렇죠, 분당 천만 원이네?
돌직구:
내 생각에 이거 튜닝하면 1, 2초 이내로 나올 것 같아요.
윈드님:
그럴 수도, 안 그럴 수도 있을 텐데, 아무튼 17분보다는 훨씬 적게 걸리겠죠.
돌직구:
이런 문제는 너무 상식 밖이잖아요?
이거는 하드웨어 문제가 아닐 가능성이 훨씬 높습니다.
하여튼 뭐, 많이 돌아왔어요. 잠시 딴 얘기를 좀 갔는데, '튜닝'이라는 단어 때문에.
이런 식의 웃긴 얘기, 진짜 많습니다.
정리를 해보면 지금까지 우리가 1시간까지 온 거죠?
그리고 5분까지 줄이던 얘기를 하고 있는데, 그 줄인 기법 중에 튜닝이라는 게 있는 거죠.
윈드님:
이거를 말로만 들어서 이해하기는 좀 어려울 같긴 한데.
지금 말씀드리는 거는, 여기에 원래 자료 구조는 Pivot데이터였어요.
이 Pivot 데이터는, DB용 자료 구조가 아니죠.
돌직구:
그럼 좋아요, 잠깐만요.
Pivot 데이터, 난 그게 뭔지 잘 모르겠는데…
이렇게 격자로 나눠놨잖아요, 그죠? 그러면 Pivot 데이터라면 설마, 그러지 않았을 것 같은데.
이 한 세트에, 이 칸 하나의 값이 하나씩 있는 거잖아요, 쉽게 말하면?
그거 그대로 DB를 넣은 거예요?
누가 그렇게 했대요?
윈드님:
전 모르죠? 이미 그리 돼 있었는 걸.
돌직구:
그러니까, Pivot형 데이터라는 거는, 이 x축, y축의 교차점이 의미가 있는 걸 말해요.
여기는 위도, 경도, 그 다음에 그 앞에 시간 값이 있겠죠.
그랬을 때, '어떤 값이', '몇이다.'
이런 자료 구조를 말하는데. 이거는 통계 자료지, Pivot 데이터는 통계 데이터지, DB 저장 용도로는 아주 안 좋은 거거든요. 이렇게 저장을 했다고요?
윈드님:
처음 자료 구조가 그렇게 되어 있었죠.
돌직구:
알겠습니다.
윈드님:
이거를 이제 DB용 자료 구조로 바꾸는 작업을 했던 거고요.
돌직구:
그러니까 DB에…
참, 말이 안 나오는데…
그냥 어이가 좀 없는데, 하여튼 그래서, 'DB에 데이터가 있으니까, DB가 좋아하는 자료 구조를 써야 된다,' 이런 얘기죠?
그러니까 일반적인 상식으로는, 이렇게 저장하는 게 맞긴 맞죠.
이 세트를 저장하는 게. 하여튼 그렇습니다
윈드님:
일단은 DB가 가장 빠르게 인식할 수 있는 구조로 바꿔준 거예요.
돌직구:
그래서 자료 구조 바꾸니까 5분이 된 거예요.
윈드님:
세상 일이 그렇게 호락호락한가요?
그 다음에 대용량 데이터는 '테이블 파티셔닝'이라는 개념이 되게 중요해요.
돌직구:
그거 뭡니까?
윈드님:
'파티션,' 말 그대로 우리 사무실에 파티션 나누잖아요.
그런 의미로 해서, 겉으로 볼 때는 이게 하나의 데이터 테이블인데, 실제로는 여러 구역에 나눠서 저장시켜서, 데이터 다루는 속도를 높이는 기법이에요.
돌직구:
그러니까 방을 나눠서 담고, 이제 검색 필요할 때는 그 방만 검색하면 되는 거내요.
윈드님:
그렇죠. 전체 이론적으로는 300억 건에서 어떤 데이터를 찾으려면, 300억 건을 뒤져야 되는 거잖아요?
근데 여기는, 연도별로 파티셔닝을 해서 저장을 시켰어요.
그러니까 필요한 연도만 검색하면 되니까 검색이 빨라진 거죠.
돌직구:
그러면 파티셔닝을 하더라도. 모든 연도에 대해서 다 검색하면 별로 의미가 없겠는데요?
윈드님:
그렇지도 않아요. 각각을 검색하는 게 빨라졌으니까, 모든 데이터에 대해서도 검색하는 데 이점이 있어요.
년도 별로 딱 집어서 뽑는 것처럼 극대화되지는 않겠지만 분명 이점이 있는거죠.
돌직구:
무슨 말인지 알겠습니다. 그래서 자료 구조 바꾸고, 파티셔닝 하니까, 5분이 된 거예요?
윈드님:
호락 호락 하지가 않다니까요. 그 다음이 '인덱싱'이에요.
근데 이거를 설명하려면 너무 깊게 들어가야 하니까, 이건 생략을 할게요.
그 외에도 DB 설정 변경을 하고요, 등등 이렇게 해서 수행한 작업들이 되게 많아요.
그 모든 작업의 결과로 인해서 5분이 나오게 되는 거죠.
돌직구:
지금 굉장히 극단적인 변화거든요?
이런 극단적인 변화가 있었다는 거는, 뭔가 꽤 많은 노력을 했다는 얘기겠죠.
고생하셨습니다.
이게 이제 연구소 잖아요? 연구소가 이런 데이터가 되게 많아요.
그리고 그거를 심지어는, 여기도 워낙 많으니까 엑셀로 안 하고 DB로 하다가, DB가 이제 안 되니까 저희한테 의뢰를 한 것 같은데.
어떤 데는…
윈드님:
엑셀로 갖고 있는 데도 있어요.
돌직구:
그렇죠. 병원들 이렇게 보면은 병원에도 연구소가 있잖아요?
그럼 거기도 임상 데이터를 엑셀로 가지고 있고…
우리 그런 것도 많이 했잖아요?
8시간이 5분이라고 생각하지 말고.
네 시간이 5분이 됐다는 거를 생각을 해봅시다.
이건 진짜 어마어마한 거네요. 돈 쓸 만하네.
그렇죠?
그래서 연구 데이터도 이렇게 굉장히 많이 쌓이고.
여기 제가 알기로 15분 간격인가? 그걸로 측정한다고 그러던데.
10분인가 15분인가 뭐 하여튼, 그렇게 계속 쌓이는 거 아니에요, 전국의 격자 좌표가.
어마어마한 거죠.
그런 것도 있고, 제조 공장에 MES라는게 있어요.
생산하는 기계에다 센서 붙여가지고…
그러니까 보통 이제 ERP라 그러면, '몇 시부터, 몇 시까지, 몇 개 생산했음,' 이렇게 한 줄 적히는데.
근데 MES같은 경우는 생산 하나 할 때마다 적는 거죠. 그런 건 데이터가 엄청 많아지는 거죠.
윈드님:
옛날에 제가 했던 걸 보면은, 컨베이어 벨트 타고, TV, 모니터를 만드는데, 흘러가는데, 구간이 한 8구간이 있어요.
바코드를 계속 찍으면은요, 그게 DB에 계속 나와요.
'적합, 적합, 적합, 적합, 적합.'
이러면서 데이터들이 쫙 쌓이거든요. 하나에 대해서도 막 거기는 한 50개 정도 쌓여요.
돌직구:
그리고 그런 거, 어디에 센서가 있는데, 그 센서에서 1초에 한 번 리포트 하는 이런 것도 있어요.
그리고 이제 나중에 그거 가지고 분석해야 되고.
하여튼 이런 거는 제가 항상 하는 말씀입니다만.
그 데이터 작업하시는 분들이 가만히 보면은, 그분들이 데이터를 가공하는 데 전문가들이 아니에요.
그분들은 정보를 보고 해석해서 결국은 뭔가 의사 결정을 해야 되는 사람들인데, 데이터를 만드는 데 시간을 너무 많이 쓰는 거죠.
홍보 같은 데, 저희 같은 사람들한테 맡기시고, 저희가 하면 금방 데이터 주잖아요.
그럼 그걸 가지고 더 중요한 일을 해야 되는 거죠.
오늘은 이 정도로 마무리하겠습니다. '4시간이 5분이 됐다,' 엄청난 성과라고 생각합니다.
수고 많이 했어요.
윈드님:
네.
----------------------------------------------------------------------------------------------
